

یکی از محصولات کمپانی قدرتمند هیولت پاکارد ، سرور تیغه ای HP BL460c G9 می باشد . این محصول می تواند جهت استفاده در دیتا سنتر و مجازی سازی مناسب باشد ، همچنین جهت پیکربندی و توسعه در محدوده وسیع طراحی شده است . قابلیت انعطاف پذیری سرور BL460c G9 به گونه ایست که امکانات ذخیره سازی بیشتر و عملیات I/O سریعتری را به ارمغان می آورد. همچنین توان پردازشی قدرتمندتر در این محصول ، جهت برآورده کردن نیاز انواع بار کاری با TCO کمتر ، عرضه گردیده است . تمام قابلیت های فوق الذکر این دستگاه ، توسط HPE OneView مدیریت می شوند که از یک پلت فرم مدیریتی یکپارچه جهت تسریع سرویس ها ، بهره می برد .
قیمت سرور BL460c G9 مانند سایر محصولات هم رده خود از خانواده پردازنده های Intel® Xeon® E5-2600 v4 پشتیبانی می کند ، این پردازنده نسبت به نسل قبلی 211% افزایش عملکرد دارد ، همچنین 2400MT/s HPE DDR4 SmartMemory را عرضه می دارد که توان عملیاتی را حداکثر 33% افزایش می دهد .
از دیگر قابلیت های سرور HP BL460c G9 می توان به موارد زیر اشاره کرد :
**• پشتیبانی از گزینه های Tiered Storage Controller
**• ارائه دادن 12Gb/s SAS
**• ارائه 20Gb FlexibleLOMs
**• فراهم آوردن 2 عدد NVMe ، M.2 و حداکثر 4 عدد درایو uFF
**• ارائه دادن گزینه های HPE ProLiant Persistent Memory
پیشنهاد می شود جهت آشنایی بیشتر با سرورهای Blade ، مطلب زیر را مورد مطالعه قرار دهید :
قیمت سرور BL460c g10

امروزه سازمان ها به دنبال این هستند که عملکرد کسب و کار خود را توسعه داده و بار کاری خود را اعم از سنتی و هیبریدی ، به شکل ایمن بر روی یک زیر ساخت یکپارچه ، همگام کنند .
سرور HP BL460c g10 از جمله محصولاتی است که توسط کمپانی HPE تولید و روانه بازار شد . این سرور جهت پیکربندی و توسعه در محدوده وسیع طراحی شده است ، علاوه بر این قابلیت انعطاف پذیری این دستگاه ، امکانات ذخیره سازی بیشتر و عملیات I/O سریعتری را به ارمغان می آورد. همچنین توان پردازشی قدرتمندی که سرور BL660 G10 ارائه می دهد ، جهت برآورده کردن نیاز انواع بار کاری با TCO کمتر ، عرضه گردیده است . تمام قابلیت های فوق الذکر این محصول ، توسط HPE OneView مدیریت می شوند که از یک پلت فرم مدیریتی یکپارچه جهت تسریع سرویس ها ، بهره می برد .
سرور BL460c G10 مانند سایر محصولات هم رده خود از خانواده پردازنده های قابل ارتقاء ®Intel® Xeon پشتیبانی می کند ، این پردازنده نسبت به نسل قبلی 25% افزایش عملکرد دارد . همچنین این دستگاه از 2666MT/s HPE DDR4 SmartMemory نیز برخوردا است .
از دیگر قابلیت های سرور HP BL460c g10 می توان به موارد زیر اشاره کرد :
**• پشتیبانی از گزینه های Tiered Storage Controller
**• ارائه دادن Internal 12 Gb/s SAS
**• ارائه 20Gb FlexibleLOMs
**• فراهم آوردن 2 عدد NVMe ، M.2 و حداکثر 4 عدد درایو uFF
**• ارائه دادن گزینه های HPE ProLiant Persistent Memory
**•
HPE BladeSystem c3000 Enclusure
با توجه به افزایش روز افزون حجم داده ها و اطلاعات ، طبیعی است که سازمان ها نیازمند سروری باشند که بتواند در مواجه با هر حجم داده ای ، مقیاس پذیر باشد . سرور HP ProLiant BL660c G9 محصولی از کمپانی HPE می باشد که در رده سرور های Blade روانه بازار شد . این محصول با پشتیبانی از 4 پردازنده جهت استفاده در مجازی سازی ، پایگاه داده و داده هایی که نیازمند پردازش بالایی هستند ، بسیار مناسب است.
قابلیت انعطاف پذیری که سرور BL660c G9 ارائه می دهد ، امکانات ذخیره سازی بیشتر و عملیات I/O سریعتری را به ارمغان می آورد. همچنین توان پردازشی قدرتمندتر در این محصول ، جهت برآورده کردن نیاز انواع بار کاری با TCO کمتر ، عرضه گردیده است .
تمام قابلیت های فوق الذکر این محصول ، توسط HPE OneView مدیریت می شوند که از یک پلت فرم مدیریتی یکپارچه جهت تسریع سرویس ها، برخوردار است .این دستگاه از پردازنده Intel Xeon E5-4600 v3/v4 پشتیبانی می کند که همراه با فن آوری 4 سوکت blade بوده و تراکم بهینه را بدون تغییر عملکرد ارائه می دهد . از جمله دیگر ویژگی های سرور BL660c G9 پشتیبانی از HPE DDR4 SmartMemory است که در مقایسه با نسل قبلی 331% افزایش عملکرد دارد .
از دیگر قابلیت های سرور HP BL660c G9 می توان به موارد زیر اشاره کرد :
**• پشتیبانی از 2 عدد NVMe SSDs
**• پشتیبانی از امکانات Tiered Storage Controller
**• ارائه دادن 12Gb/s SAS
**• فراهم آوردن 20Gb FlexibleLOMs ، M.2 و USB 3.0
1 این سرور از کمپانی HPE با قابلیت پشتیبانی از DDR4 ، عملکرد را 14 تا 33 درصد بهبود بخشیده است .
پیشنهاد می شود جهت آشنایی بیشتر با سرورهای Blade ، مطلب زیر را مورد مطالعه قرار دهید :
مجازی سازی دسکتاپ
VMware محصولات گوناگونی از Horizon را عرضه کرده است که همه این محصولات برای ارائه خدمات به کاربران در یک مجموعه واحد به نام VMware Horizon Suite قرار می گیرند. ادمین با استفاده از مجموعه Horizon می تواند دسکتاپ ها، اپلیکیشن ها و داده را در سراسر انواع endpoint ها توزیع کند و پاسخگوی تقاضای کاربران برای دسترسی به فایل ها و داده ها در انواع دستگاه ها و در محیط خانه، اداره و … باشد. این مجموعه شامل راهکارهای Horizon View، Horizon Mirage و Horizon Workspace می شود و از قابلیت های زیر پشتیبانی می کند:
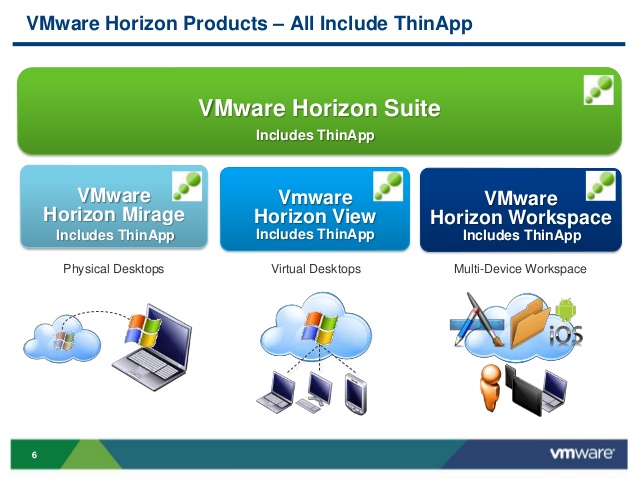
Horizon View یک راهکارِ مجازی سازی دسکتاپ
مهمترین بخش در Horizon view واسط اتصال یا همان View Manager است که کاربران را به دسکتاپ های مجازی موجودشان در دیتاسنتر متصل می کند. همچنین View شامل پروتکل نمایش از راه دور PCoIP است که جهت ارائه بهترین تجربه کاربری ممکن ، تحت ارتباطات LAN یا WAN استفاده می شود. در نتیجه به کاربر یک دسکتاپ شخصی قدرتمند برای دسترسی به داده، اپلیکیشن ها، ارتباطات یکپارچه (صوت، تصویر و ) و گرافیک 3D تعلق می گیرد.
علاوه بر موارد ذکر شده، Horizon View شامل ThinApp برای مجازی سازی اپلیکیشن و Composer (برای اینکه به سرعت image های دسکتاپ را از طریق یک golden image ایجاد کند) می شود. کاربران از طریق چندین روش می توانند به دسکتاپ های مجازی خود متصل شوند که شامل View software client بر روی لپتاپ، View iPad یا Android client، مرورگر وب یا یک دستگاه thin-client می شود.
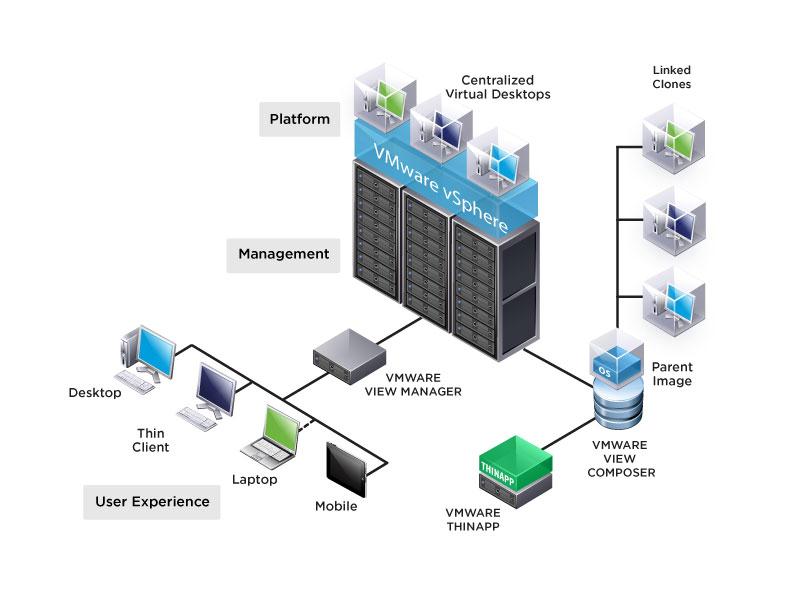
برخی از مولفه های اصلی در Horizon View عبارتند از:
کمپانی VMware راهکار Mirage را در سال 2012 از شرکت Wanova خریداری نمود و در مجموعه VMware Horizon Suite قرار داد. Mirage راهکاری منحصر به فرد برای مدیریت متمرکز دسکتاپ های فیزیکی یا مجازی، لپ تاپها و یا دستگاه های شخصی مورد استفاده در محیط کار است. هنگامی که Mirage بر روی یک windows PC نصب شده باشد، کپی کاملی را از آن Windows بر روی دیتاسنتر قرار می دهد و آنها را با یکدیگر همگام نگاه میدارد. این همگام سازی شامل تغییراتی از جانب کاربر نهایی در windows می شود که بر روی دیتاسنتر بارگذاری می شوند. همچنین شامل تغییراتی از جانب مدیر شبکه در رابطه با IT است که دانلود شده و به طور مستقیم بر روی windows PC کاربر اعمال می شود. Mirage توانایی مدیریت مرکزی image های دسکتاپ ها را دارد در حالی که مجوز مدیریت محیط local کاربر را به خود کاربرنهایی نیز می دهد.
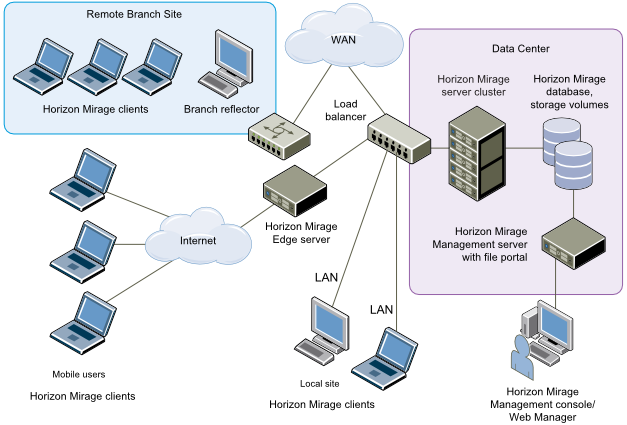
Mirage می تواند PC را به لایه هایی مجزا تقسیم کند که به طور مستقل مدیریت می شوند: لایه Base Image، یک لایه شامل اپلیکیشن هایی نصب شده توسط کاربر و اطلاعات ماشین همچون machine ID و یک لایه شامل داده و فایل های شخصی کاربر.
در این روش، مدیر IT می تواند یک read-only Base Image ایجاد کند که معمولا شامل سیستم عامل (OS) و اپلیکیشن های اصلی همچون Microsoft Office و راهکارهای آنتی ویروسی می شود که به صورت مرکزی مدیریت می شوند. این Base Image می تواند بر روی کپی ذخیره شده از هر PC مستقر شود و سپس با نقطه نهایی هماهنگ شود. به دلیل لایه بندی، Image می تواند patch، بروزرسانی و re-synchronized شود، بدون اینکه اپلیکیشن های نصب شده توسط کاربر یا داده را بازنویسی کند. این ویژگی منجر به بهینه سازی در عملیات شبکه خواهند شد و موارد استفاده زیر را خواهد داشت:
برخی از مولفه های موجود در VMware Mirage عبارتند از:
یک نرم افزار مدیریت اینترپرایز است که واسط مرکزی واحدی را جهت دسترسی ایمن فراهم می کند. شما در هر زمان و از هر مکانی می توانید از طریق لپتاپ خود، کامپیوترهای خانگی و دستگاه های موبایل android یا ios به اپلیکیشن ها، دسکتاپ ها، فایل ها و سرویسهای وب کمپانی دسترسی یابید
مدیران شبکه از طریق پلتفرم مدیریت مبتنی بر وب می توانند مجموعه ای customize از دسترسی به اپلیکیشن و داده را برای کاربران فراهم کنند که شامل تنظیمات security policy و مجوز استفاده از اپلیکیشن ها می شود. سازمان ها می توانند به سادگی دستگاه های جدید، کاربران جدید یا اپلیکیشن های جدید را برای یک گروه از کاربران بدون نیاز به کانفیگ دوباره دستگاه ها یا endpoint ها اضافه کنند.
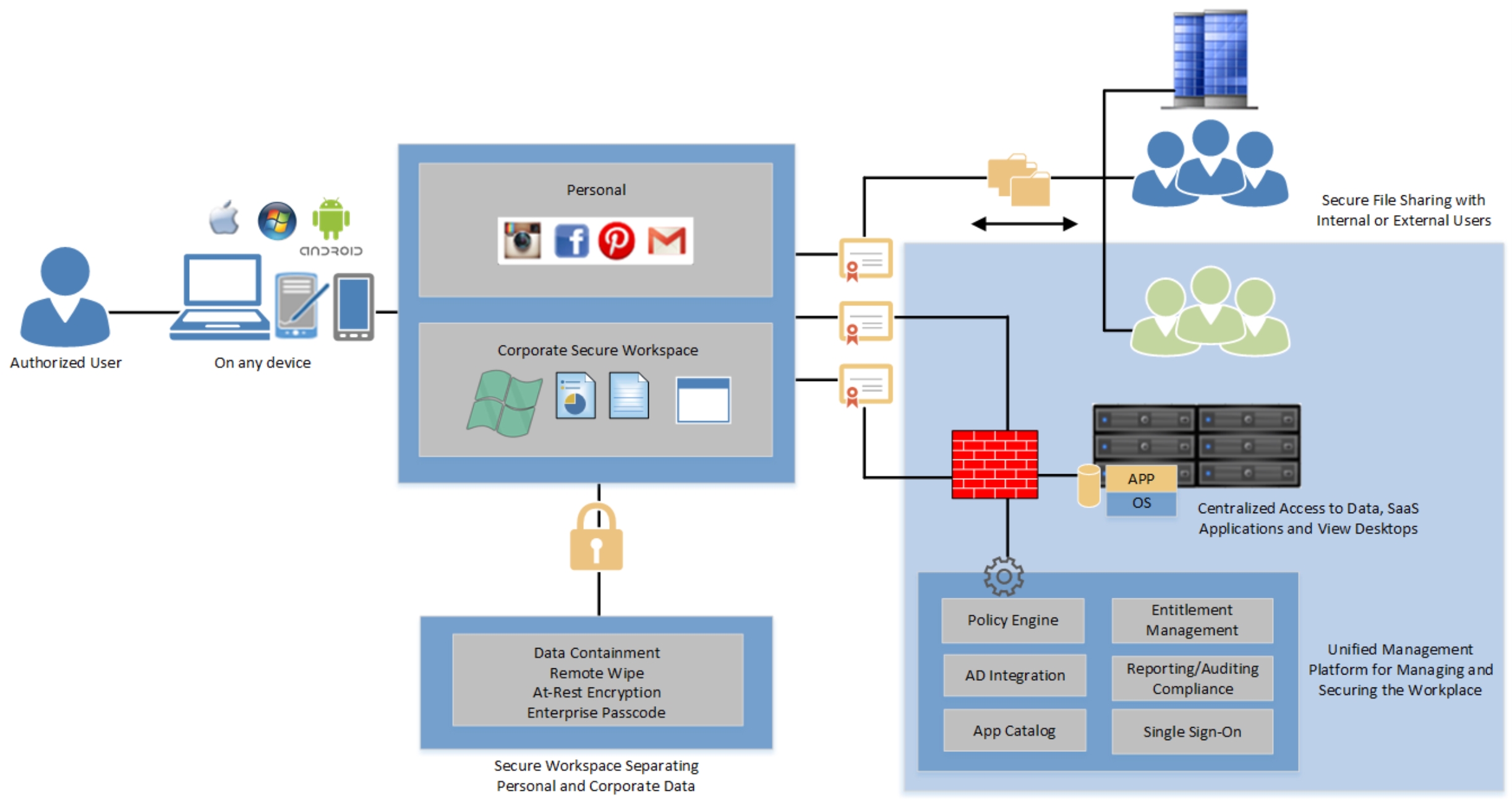
برخی از مولفه های اصلی در Horizon Workspace عبارتند از:
پشتیبان گیری از اطلاعات
یکی از اساسی ترین مسایل برای فهم پشتیبان گیری (backup) و بازیابی (recovery) ، مفهومِ سطوح backup است و اینکه هر یک از این سطوح چه معنایی دارند.
فقدانِ درک صحیح از اینکه این سطوح چه هستند و چگونه به کار گرفته می شوند، منجر شده است که سازمان ها تجربه ناخوشایندی از پهنای باند و فضای ذخیره سازی به هدر رفته ای داشته باشند که جهت از دست نرفتن داده های مهم در پشتیبان گیری از اطلاعات
Full backup
پشتیبان گیریِ کامل، شامل همه داده های کل سیستم می شود. بکاپ کامل از Windows system ، باید کپی هر یک از فایل ها بر روی هر درایو از ماشین یا VM را در برگیرد.
تنها چیزی که در پشتیبان گیری کامل حذف می شود، فایل هایی هستند که از طریق پیکربندی مستثنا می شوند. به طور مثال، اکثر ادمین های سیستم تصمیم می گیرند که دایرکتوری هایی را که در طول بازگردانی ارزشی ندارند (به طور مثال، /boot یا /dev) یا دایرکتوری های شامل فایل های موقتی (به طور مثال، C:\Windows\TEMP در ویندوز، یا /tmp در لینوکس) حذف شوند.
در مورد اینکه فرآیند پشتیبان گیری از اطلاعات شامل چه فایل هایی باید شود، دو رویکرد وجود دارد: از همه چیز بکاپ بگیرید و چیزهایی را که می دانید به آنها نیاز ندارید را حذف کنید، یا اینکه تنها چیزی را که می خواهید از آن بکاپ بگیرید، انتخاب کنید. اولین رویکرد گزینه ای امن تر است و رویکرد دوم نیز منجر به صرفه جویی در فضای سیستم از اطلاعات شما خواهد شد. برخی معتقدند که پشتیبان گیری از فایل های اپلیکیشن همچون دایرکتوری های شاملSQL Server یا Oracle ، بیهوده است و به سادگی در طول فرآیند بازگردانی، اپلیکیشن را دوباره بارگذاری می کنند. مشکل رویکرد اخیر این است که احتمال دارد شخصی داده ای ارزشمند را در یک دایرکتوری قرار دهد که برای پشتیبان گیری انتخاب نشده است. به فرض اگر شما تنها دایرکتوریِ home/ یا D:\Data را برای پشتیبان گیری برگزینید، چگونه سیستمِ بکاپ تشخیص خواهد داد که شخصی اطلاعاتی مهم را در دیگر دایرکتورها ذخیره کرده است؟ به همین دلیل، با وجود اینکه رویکرد اول فضای زیادتری را اشغال می کند، پشتیبان گیری از همه چیز روشی امن تر می باشد و تنها فایلهایی که نیازی ندارید، حذف می شوند. البته اگر شما یک محیطِ به شدت کنترل شده داشته باشید که در آن همه داده ها در مکانی مشخص بارگذاری شده باشند و راهکار هماهنگ شده ی مناسبی برای جابجایی سیستم عامل و اپلیکیشن ها در فرآیند بازگردانی داشته باشید، استفاده از راهکار دوم برایتان موثر خواهد بود.
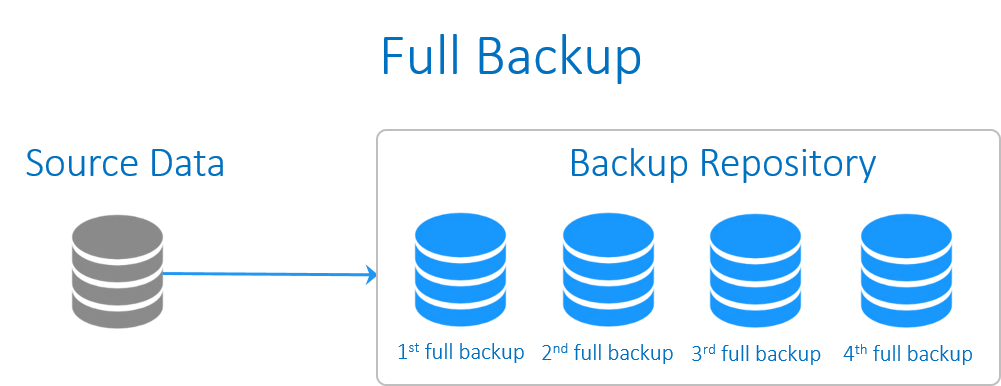
از آنجایی که حجم عظیمی از داده ها باید کپی شوند، در این فرآیند زمان بسیاری صرف خواهد شد (در مقایسه با انواع دیگر از روش های بکاپ گیری از اطلاعات ، این روش 10 برابر زمان بیشتری را صرف می کند). در نتیجه در هر نوبتِ پشتیبان گیری، بارکاری قابل ملاحظه ای به شبکه تحمیل می شود و با عملیات روتینِ شبکه شما تداخل پیدا می کند. همچنین بکاپ گیری از اطلاعات به طور کامل حجم بالایی از فضای ذخیره سازی را نیز اشغال می کند.
به همین دلیل است که بکاپ گیری از اطلاعات به طور کامل تنها به صورت دوره ای گرفته خواهد شد و آن را با انواع دیگر بکاپ ترکیب می کنند.
با وجود اینکه بکاپ گیری از اطلاعات به طور کامل، مزیت های بالا را برای شما به ارمغان می آورد اما شامل نقاط ضعف بسیاری نیز هست:
بکاپِ افزایشی معمولا از داده هایی پشتیبان می گیرد که از زمان آخرین بکاپِ گرفته شده (هر نوعی از بکاپ که باشد)، تغییری روی آنها صورت گرفته باشد. گرفتن یک بکاپِ کاملِ اولیه از پیش شرط های ایجادِ بکاپِ افزایشی است. و بسته به ت های ذخیره سازیِ بکاپ، پس از یک دوره زمانی معین به یک full backup جدید برای تکرار این سیکل نیاز است.
برخی از این نوع بکاپ ها، بکاپ های file-based هستند به این معنا که از همه فایلهایی که نسبت به آخرین زمان بکاپ تغییر کرده باشند، بکاپ تهیه می شود. در حالی که ما به روش های مختلف می کوشیم تا تاثیر I/O ناشی از بکاپها بر روی سرور (به خصوص به هنگام پشتیبان گیری از VM ها) را کاهش دهیم، در این شیوه بکاپ گیری از اطلاعات با چالشی در این مورد مواجه خواهیم شد. چرا که پشتیبان گیری از یک فایل 10GB که تنها 1 MB از آن تغییر کرده است، چندان کارآمد نیست.
به دلیل ناکارآمدی در شیوه file-based، اکثر کمپانی ها به سمت بکاپ افزایشیِ block-based رفته اند که در آن تنها از بلاک های تغییر یافته، بکاپ گرفته می شود. رایجترین روش برای انجام آن هنگامی است که از محصولات نرم افزاری بکاپ تهیه می شود، به طور مثال از VMware یا
Hyper-V با استفاده از API هر یک از آنها، می توان پشتیبان تهیه نمود. هر App یک API مناسب خود را اعلام می کند که بکاپ افزایشیِ block-based را انجام می دهد.
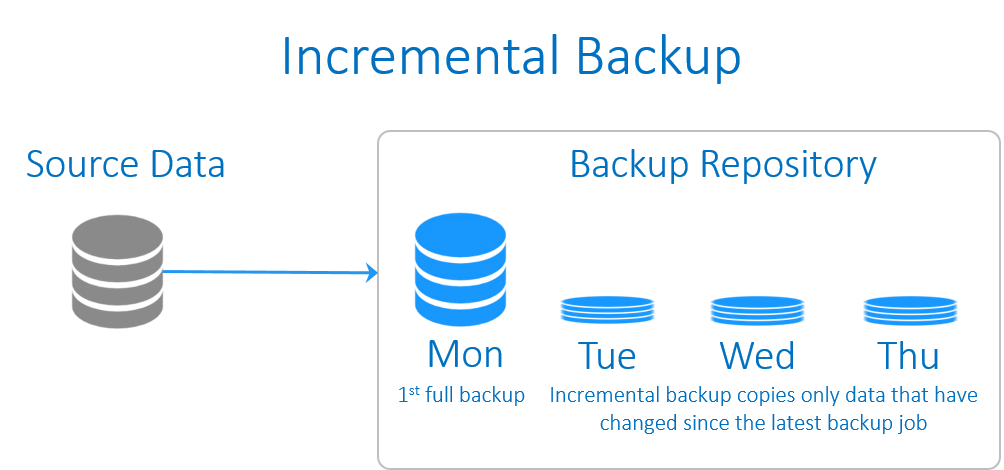
از لحاظِ سرعتِ پشتیبان گیری/بازگردانی، بکاپ differential به عنوانِ راهکاری است که در میانِ دو راهکار بکاپِ کامل و بکاپ افزایشی قرار می گیرد:
فضای ذخیره سازی لازم برای بکاپِ differential، حداقل در یک دوره مشخص، کمتر از فضای لازم برای بکاپِ کامل و بیشتر از فضای مورد نیاز برای بکاپ افزایشی است.
این راهکار مشابه با بکاپ گیری از اطلاعات به طور کامل است. این نوع بکاپ گیری از اطلاعات، کپی دقیقی از مجموعه داده ها ایجاد می کند با این تفاوت که بدون ردیابیِ نسخه های مختلفِ فایل ها، تنها آخرین نسخه از داده در بکاپ ذخیره می شود.
بکاپِ Mirror ، فرآیند ایجاد کپی مستقیمی از فایل ها و فولدرهای انتخاب شده، در زمانی معین است. از آنجایی که فایل ها و فولدرها بدون هیچ گونه فشرده سازی در مقصد کپی می شود، سریع ترین
انواع روش های پشتیبان گیری از اطلاعات است. با وجود سرعت افزایش یافته در آن، نقاط ضعفی را نیز به همراه خواهد داشت: به فضای ذخیره سازی وسیعتری نیاز دارد و نمی تواند از طریق رمز عبور محافظت شود.
در این نوع از بکاپ گیری، هنگامی که فایل های بی کاربرد حذف می شوند، از روی بکاپِ mirror نیز حذف خواهند شد. بسیاری از خدماتِ بکاپ ، بکاپِ mirror را با حداقل 30 روز فرصت برای حذف پیشنهاد می کنند. به این معناست که به هنگام حذف یک فایل از منبع، آن فایل حداقل 30 روز بر روی storage server نگهداری می شود.
امتیازی که بکاپِ mirror در اختیار شما می گذارد، بکاپی درست است که شامل فایل های منسوخ شده و قدیمی نمی شود.
و اما معایب آن زمانی خود را نشان خواهد داد که فایل ها به صورت تصادفی یا به واسطه ویروس ها از منبع حذف شده باشند.
در این نوع بکاپ گیری از اطلاعات نیز برای شروع به یک بکاپ کامل اولیه نیاز است. پس از ایجاد بکاپِ کامل اولیه، هر بکاپ افزایشیِ موفق تغییرات را به نسخه پیشین اعمال می کند که در نتیجه آن در هر زمان یک بکاپ کاملِ جدید (به صورت مصنوعی) ایجاد می شود. در حالی که کماکان توانایی بازگشت به نسخه های پیشین وجود دارد. هر یک از بکاپ های افزایشیِ اعمال شده به بکاپ کامل، نیز ذخیره می شوند که در زنجیره ای از بکاپ ها، به طور مستمر در پشت سرِ بکاپ کاملِ به روز شده، در جریان هستند.
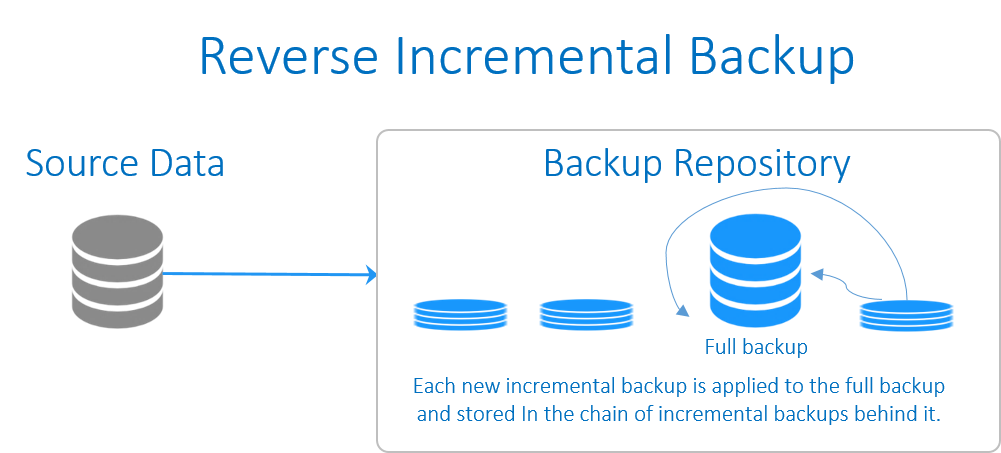
امتیاز اصلی در این نوع از بکاپ گیری فرآیند بازیابی کارآمدترِ آن است، چرا که بخش زیادی از جدیدترین نسخه های داده به بکاپ کامل اولیه اضافه می شود و نیازی ندارید بکاپ های افزایشی را در طول بازیابی بکار ببندید. در گیف زیر فرآیند اجرای این نوع بکاپ نشان داده شده است.
پشتیبان گیری هوشمند، ترکیبی از بکاپ های کامل، افزایشی و تفاضلی است. بسته به هدفی که در بکاپ گیری از اطلاعات در نظر دارید و همچنین فضای ذخیره سازیِ در دسترس، بکاپ هوشمند می تواند راهکاری کارآمد را ارائه دهد. جدول زیر ایده ای در رابطه با چگونگی کارکرد این نوع بکاپ، در اختیار شما می گذارد.

با استفاده از بکاپ هوشمند، همیشه می توانید تضمین نمایید که فضای ذخیره سازیِ کافی برای بکاپ های خود در اختیار دارید.
بر خلاف بکاپ های دیگر که به صورت دوره ای انجام می شوند، CDP از هر تغییری در مجموعه داده های منبع log تهیه می کند که از سویی مشابه با بکاپِ mirror است. اختلاف CDP با mirror در این است که log مربوط به تغییرات برای بازیابیِ نسخه های قدیمی تر از داده می تواند بازیابی شود.
این نوع از بکاپ شباهت های بسیاری با بکاپ افزایشی مع دارد. اختلافِ آنها در چگونگی مدیریت داده هاست. بکاپ کامل مصنوعی با اجرای بکاپ کاملِ مرسوم آغاز می شود که در ادامه مجموعه ای از بکاپ ها افزایشی را در پی دارد. در زمانی معین، بکاپ های افزایشی هماهنگ می شوند و به بکاپ کاملِ موجود اعمال می شوند تا بکاپ کاملی را به طور مصنوعی و به عنوان یک نقطه شروعِ جدید ایجاد نمایند.
بکاپ کاملِ ساختگی، تمامی امتیازات یک بکاپ کامل را دارد، در حالی که زمان و فضای ذخیره سازیِ کمتری را صرف می کند.
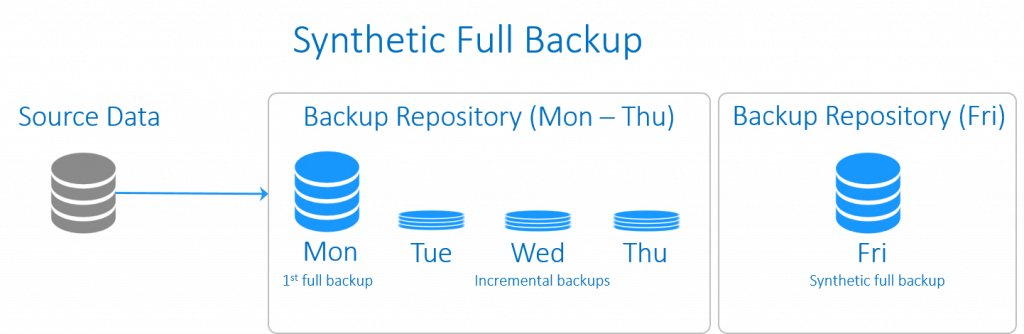
از جمله مزایای بهره وری از بکاپ کامل ساختگی عبارتند از:
این راهکار با بکاپ افزایشی عادی متفاوت است. همچون اکثر راهکارهای پیشین برای شروع به یک بکاپ کامل اولیه به عنوان یک نقطه مرجع برای ردگیری تغییرات نیاز دارد. از آن لحظه، تنها بکاپ های افزایشی بدون هیچ گونه بکاپ کاملِ دوره ای ایجاد می شوند.
فرض کنید که شما بکاپ کامل را در روز شنبه ایجاد کردید. با شروع روز بعد، بکاپ های افزایشی به صورت روزانه ایجاد می شوند. در روز یکشنبه دو بلوک جدیدِ A و B در مجموعه داده های منبع ایجاد شده اند. در روز دوشنبه بلوک A حذف و بلوکِ جدید C بر روی منبع ایجاد شده است. در روز سه شنبه بلوک B حذف و بلوک جدید D ایجاد شده است. سیستمِ forever-incremental backup تمامیِ تغییرات روزانه را پیگیری می کند. حذف بلوک های داده تکراری تا فضای ذخیره سازی مورد نیاز برای بکاپ را کاهش دهد.
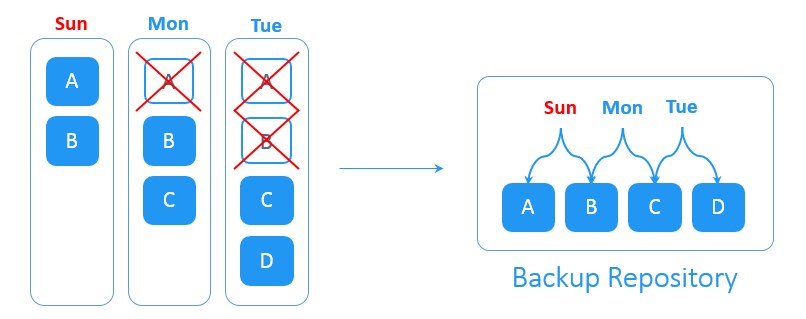
یا توجه به ت های ویژه در زمینه نگهداری بکاپ ها، پس از ایجادِ مجموعه ای از بکاپ های افزایشی، نقاط بکاپ گیری و بازیابیِ منقضی شده حذف می شوند تا فضای ذخیره سازیِ اشغال شده در backup repository آزاد شود.
امتیازاتی که روش بکاپ گیریِ forever-incremental نصیب شما خواهد کرد نیز مشابه با روشِ بکاپ کامل ساختگی است.
در حقیقت راهکار بکاپ گیری از اطلاعات خوب یا بد وجود ندارد. باید در نظر بگیرید که چه نوعی از بکاپ گیری برای شما بهترین است و نیازهای ویژه ی سازمانِ شما را بر مبنای ت های محافظت از داده، ذخیره سازِ موجود، منابع، پهنای باند شبکه، نواحی داده ای مهم و …. برآورده می سازد.
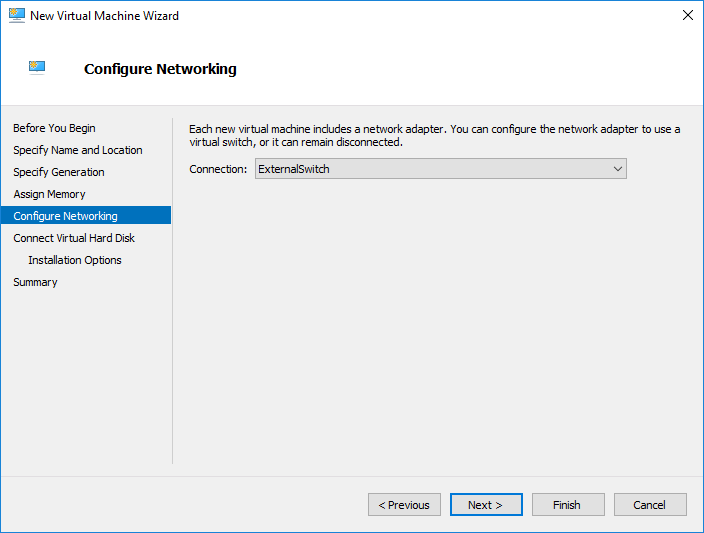
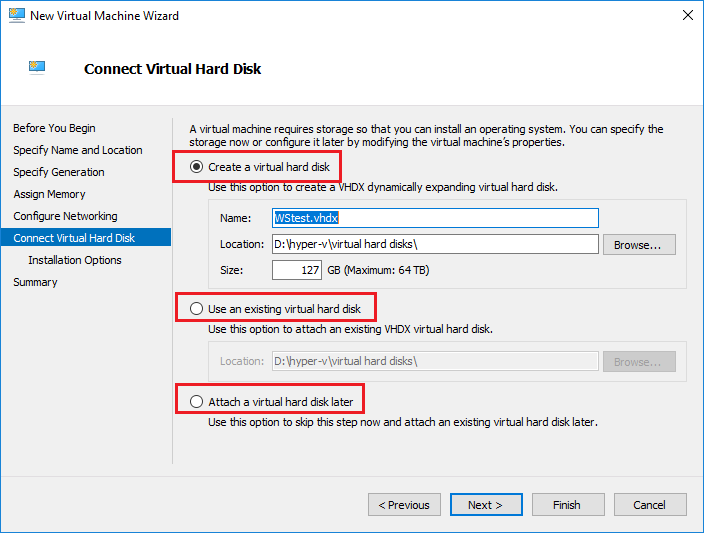
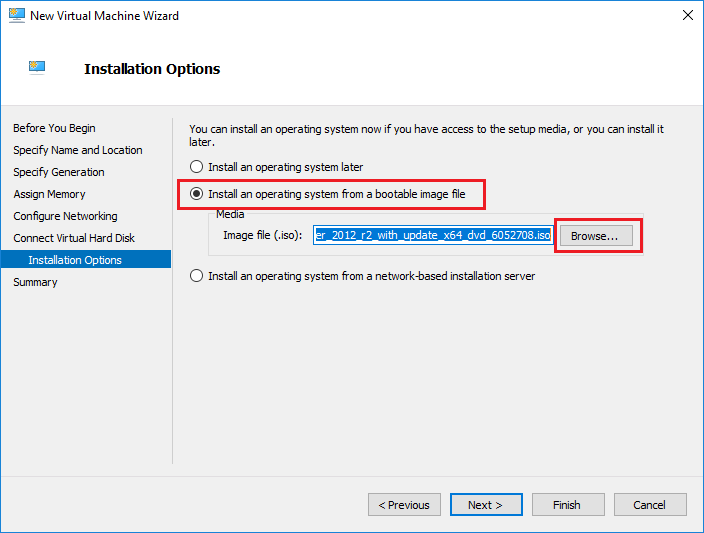
توجه: برای وضوح تصاویر بر روی آن ها کلیک کنید.
منبع :
Faradsys.com
Hyper-V features a Type 1 hypervisor-based architecture. The hypervisor virtualizes processors and memory and provides mechanisms for the virtualization stack in the root partition to manage child partitions (
virtual machines) and expose services such as I/O devices to the virtual machines.
The root partition owns and has direct access to the physical I/O devices. The virtualization stack in the root partition provides a memory manager for virtual machines, management APIs, and virtualized I/O devices. It also implements emulated devices such as the integrated device electronics (IDE) disk controller and PS/2 input device port, and it supports Hyper-V-specific synthetic devices for increased performance and reduced overhead.
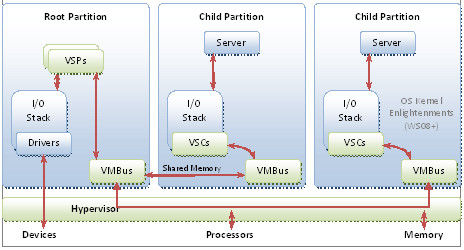
The Hyper-V-specific I/O architecture consists of virtualization service providers (VSPs) in the root partition and virtualization service clients (VSCs) in the child partition. Each service is exposed as a device over VMBus, which acts as an I/O bus and enables high-performance communication between virtual machines that use mechanisms such as shared memory. The guest operating system’s Plug and Play manager enumerates these devices, including VMBus, and loads the appropriate device drivers (virtual service clients). Services other than I/O are also exposed through this architecture.
Starting with Windows Server 2008, the operating system features enlightenments to optimize its behavior when it is running in virtual machines. The benefits include reducing the cost of memory virtualization, improving multicore scalability, and decreasing the background CPU usage of the guest operating system.
The following sections suggest best practices that yield increased performance on servers running Hyper-V role.
source:
microsoft.com
Fast VP چیست؟
نرم افزار EMC FAST به
محصولات EMC Unity اجازه می دهد تا از درایوهای Flash با کارایی بالا استفاده کنند. نرم افزار FAST شامل Fully Automated Storage Tiering برای (Virtual Pools (FAST VP و FAST Cache است. این دو ویژگی در کنار هم کار می کنند تا از فضای ذخیره سازی درون سیستم به صورت مؤثر استفاده شود. هر یک از این ویژگی های نرم افزاری تضمین می کند که فعال ترین داده ها از طریق Flash پشتیبانی می شوند.
هنگامی که ویژگیِ FAST VP فعال شود، این ویژگی آمارهایِ Performance روی هر [1] slice در یک Pool را اندازه گیری و ثبت می کند. در ادامه، FAST VP این داده ها را تجزیه و تحلیل می کند و تصمیم می گیرد تا داده ها را به tier های مختلف انتقال دهد (با توجه به میزان استفاده از داده) تا Performance یک Pool را بیشینه کند و از فضای درون Pool به طور موثری بهرمند شود. Slice هایی که بیشترین استفاده را دارند به طور خودکار به Tier های بالاتر در یک Pool منتقل می شوند، در حالی که Slice هایی که استفاده کمتری دارند به Tier های پایین تر منتقل می شوند. داده هایی که از قبل روی Flash در یک Pool قرار گرفته اند از فضای Fast Cache استفاده نمی کنند که این قابلیت اجازه می دهد تا داده های مستقرِ بیشتری بر روی هارد دیسک ها از مزایای فلش Fast VP بهره مند شوند.
این مقاله برای مشتریان ، شرکا و کارکنان
فاراد در نظر گرفته شده است که از ویژگی های FAST VP و FAST CACHE در خانواده EMC Unity از سیستم های استوریج استفاده می کنند. استفاده از این ویژگی با EMC Unity و نرم افزار مدیریت EMC همراه می شود.
بطور معمول وقتی داده ای ایجاد می شود ابتدا در بالاترین tier قرار می گیرد و با توجه به میزان نوشتن و خواندن از آن داده ، استوریج نسبت به انتقال داده در tier مناسب اقدام می کند. از این روند نیز به عنوان چرخه حیات داده ها یاد شده است. EMC Unity سیستم ذخیره سازی کاملا اتوماتیک (Fully Automated Storage Tiering) را برای Pool های مجازی (FAST VP) ارائه می دهد که بر الگوهای دسترسی به داده (خواندن و نوشتن داده ها) درونِ Pool های سیستم نظارت می کند و به صورت پویا خود را تطبیق می دهد از طریقِ در نظر گرفتن و انتخاب مناسب ترین tier که میزان کارایی (Performance) مورد نیاز را ارائه می دهد. FAST VP درایوها را به سه دسته تقسیم می کند. این سطوح عبارتند از:

FAST VP به کاهش هزینه (Total Cost of Ownership-TCO) با حفظ Performance و با استفاده از ساختار Pool می پردازد. به جای ایجاد یک Pool با یک نوع درایو، مخلوط کردن Flash، SAS و NL SAS درایوها می توانند از طریق کاهش تعداد درایوها و استفاده از درایوهایی با ظرفیت بیشتر به کاهش هزینه های یک پیکربندی کمک کنند. داده هایی که دارای سطح عملکرد بالایی هستند در درایو های Flash قرار می گیرند، در حالی که داده هایی که فعالیت کمتری دارند در SAS یا NL-SAS قرار می گیرند.
EMC Unity یک رویکرد واحد برای ایجاد منابع ذخیره سازی در سیستم دارد. Block LUNs، File Systems و VMware Datastores همه می توانند در یک Pool واحد وجود داشته باشند و همگی می توانند از ویژگی های FAST VP بهره مند شوند. در تنظیمات سیستم با حداقل مقدار Fast VP ، Flash به راحتی از درایوهای Flash برای داده های فعال با عملکرد بالا , صرف نظر از نوع منبع استفاده می کند. میزان عملکرد برای تمام داده ها در یک Pool در مقایسه با یکدیگر بررسی می شوند و بیشترین اطلاعات مورد استفاده ، در درایو های با کارایی بالا (درایو های Flash) قرار می گیرند. ت های Tiering در مقاله های بعد توضیح داده خواهد است.
لایسنس FAST VP :
در Fast VP ، Unity روی سیستم های Unity Hybrid و UnityVSA پشتیبانی می شود. برای سیستم های Unity Hybrid ، FAST VP از طریق بسته ی نرم افزاری EMC Unity Essentials که شامل تمامی سیستم های Unity Hybrid می باشد فعال می شود. FAST VP برای UnityVSA با License نرم افزار پایه فعال می شود. هنگامی که این License ها نصب می شوند، ویژگی های مرتبط FAST VP در دسترس هستند:
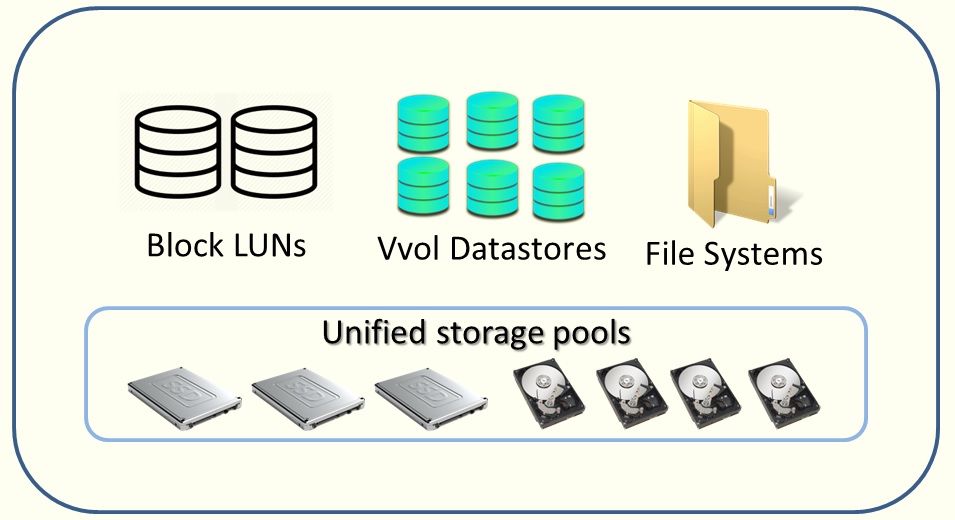
[1] Slice : سیستم LUN های شما را به تکه های کوچک (Slice) تقسیم می کند و به این Slice ها یک درجه حرارتی ( با توجه به کارایی ) اختصاص داده می شود. مثلا اگر Slice هایی که به طور مداوم در دسترس باشد را Hot Slice و Slice هایی که به ندرت از آن ها استفاده می شود را Cold Slice گویند و این Slice ها دارای حجم 256MB می باشند.
منبع : فاراد سیستم
آشنایی با پروتکل HSRP
در یک شبکه lan، اگر تمامی بسته ها به مقصد سگمنت های دیگر شبکه توسط روتری یکسان فرستاده شوند، هنگامی که gateway از کار بیافتد، همه ی هاست هایی که از آن روتر به عنوان next-hop پیش فرض استفاده می کنند در برقراری ارتباط با شبکه های خارجی موفق نخواهند بود. برای رفع این مشکل، سیسکو پروتکل اختصاصی HSRP را ارائه داده است که برای gateway ها در یک lan ، افزونگی ایجاد می کند تا قابلیت اطمینان شبکه را افزایش دهد.
پروتکل HSRP چیست ؟
یکی از راه های دستیابی به uptime نزدیک به 100 درصد در شبکه، استفاده از پروتکل HSRP
با به اشتراک گذاشتن یک آدرس IP و آدرس MAC (لایه 2) میان دو یا تعدادی بیشتری از روترها، آنها می توانند به عنوان یک روتر مجازیِ واحد (virtual router) عمل نمایند. روترهای عضو در این گروه، به طور مستمر برای رصد وضعیت روترهای دیگر پیام هایی را با یکدیگر مبادله می نمایند. در نتیجه هر روتر مسئولیت مسیریابی روتری دیگر را نیز بر عهده خواهد گرفت. و بر پایه این پروتکل، هاست ها می توانند بسته های IP را به آدرس MAC و IP پایداری ارسال نمایند.
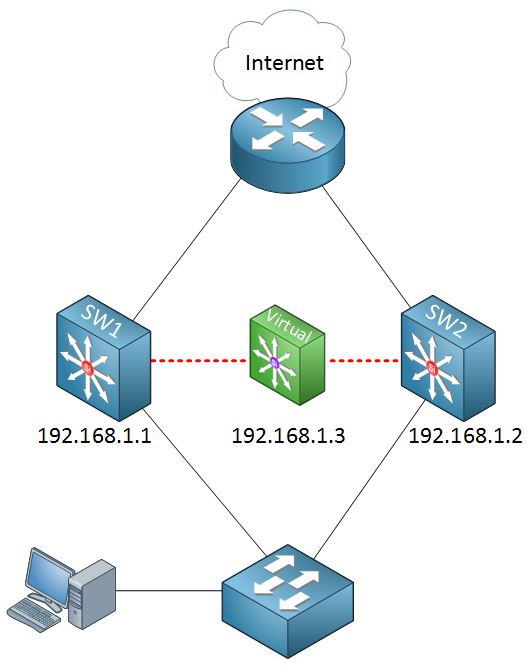
در ادامه مکانیزم های موجود برای تشخیص روتر توسط هاست تشریح می شود. بسیاری از این مکانیزم ها منجر به تاب آوری (resiliency) بیشترِ شبکه نمی شوند. این مسئله به این معنا می تواند باشد که در ابتدا برای پروتکل ها قابلیت تاب آوریِ شبکه در نظر گرفته نمی شد یا اینکه اجرای پروتکل برای هر هاست از شبکه ممکن نبود. باید این را در نظر داشته باشید که بسیاری از هاست ها، تنها مجوز تنظیمِ default gateway را به شما می دهند.
برخی از هاست ها از پروتکل (proxy Address Resolution Protocol (ARP برای انتخاب یک روتر استفاده می کنند. هنگامی که یک هاست proxy ARP را اجرا می کند، به منظور دستیابی به آدرس IP هاستی که قصد ارتباط با آن را دارد، یک درخواست ARP ارسال می کند. فرض کنید روتر A در شبکه، از طرف هاستِ مقصد پاسخ می دهد و آدرس MAC اش را در اختیار می گذارد. به واسطه ی پروتکل ARP ، هاست مبدا با هاست راه دور به گونه ای برخورد می کند که گویی به همان سگمنت از شبکه متصل است. اگر روتر A از کار بیافتد، هاست مبدا به ارسال بسته ها به هاست مقصد از طریق آدرس MAC مربوط به روتر A ادامه می دهد، با آنکه این بسته ها به مقصدی ارسال نمی شوند و از بین می روند. شما می توانید منتظر بمانید تا پروتکل ARP ، آدرس MAC یک روتر دیگر بر روی همان سگمنت ،به فرض روتر B ، را به دست آورد. آدرس روتر B از طریق ارسال یک درخواستِ دیگر ARP یا راه اندازی مجددِ هاست مبدا برای ارسال درخواست ARP به دست می آید. از طرف دیگر برای مدت زمانی قابل توجه، هاست مبدا نمی تواند با هاست راه دور ارتباط برقرار کند، با وجود اینکه انتقال بسته هایی که پیش از این توسط روتر A ارسال می شدند از طریق روتر B میسر می شود.
برخی از هاست ها یک پروتکل مسیریابی پویا همچون (Routing Information Protocol (RIP یا (Open Shortest Path First (OSPF را اجرا می کنند تا روترها را بیابند. نقطه ضعفِ پروتکل RIP، سرعتِ کُندِ آن برای به کارگیری تغییرات در توپولوژی است. اجرای یک پروتکل مسیریابی پویا بر روی هر هاست، به دلایلی ممکن است، عملی نباشد. که این دلایل شاملِ administrative overhead ، processing overhead ، مسائل امنیت یا عدم امکانِ پیاده سازی پروتکل بر روی برخی از پلتفرم ها می شود.
به هنگام عدم دسترسی پذیری به یک مسیر، برخی از هاست های جدیدتر از IRDP برای یافتن روتری جدید استفاده می کنند. هاستی که IRDP را اجرا می کند به پیام های multicast دریافت شده از روتر پیش فرضِ خود گوش فرا می دهد و هنگامی که پس از مدتی پیام های hello را دریافت نکند، از یک روتر جایگزین بهره می برد.
پروتکل DHCP مکانیزمی را برای انتقال اطلاعات کانفیگ به هاست ها بر روی شبکه TCP/IP ارائه می دهد. این اطلاعات کانفیگ معمولا شامل آدرس IP و default gateway می شود. اگر default gateway از کار بیافتد، هیچ مکانیزمی برای تغییر به روتری جایگزین وجود ندارد.
در بسیاری از هاست ها تشخیص پویا پشتیبانی نمی شود. بنا به دلایلی که پیشتر ذکر شد، اجرای یک مکانیزم تشخیص پویای روتر بر روی هر هاست از شبکه نیز ممکن است تحقق پذیر نباشد. در نتیجه پروتکل HSRP برای این هاست ها failover service را فراهم می کند.
با استفاده از HSRP ، مجموعه ای از روترها به صورت همزمان فعالیت می کنند تا به عنوان یک روتر مجازی واحد به هاست های موجود بر روی LAN نشان داده می شوند. این مجموعه به عنوان گروه HSRP یا گروه standby شناخته می شوند. یک روترِ برگزیده از این گروه مسئولیت ارسال بسته هایی را بر عهده دارد که هاست ها به روتر مجازی می فرستند. این روتر به عنوان Active router شناخته می شود و روتر دیگر به عنوان Standby router انتخاب می شود. هنگامی که روتر Active از کار بیافتد، روتر standby وظایفِ ارسال بسته را بر عهده می گیرد. با وجود آنکه تعداد دلخواهی از روترها پروتکل HSRP را می توانند اجرا نمایند، تنها روتر Active ، بسته هایی را ارسال می کند که به روتر مجازی فرستاده شده اند.
برای به حداقل رساندن ترافیک شبکه، به محض اینکه پروتکل فرآیند انتخاب را کامل کرد، تنها روترهای Active و standby پیام های HSRP را به صورت دوره ای می فرستند. اگر روتر Active از کار بیافتد، روتر standby به عنوان روتر Active فعال خواهد شد. اگر یک روتر standby از کار بیافتد یا به یک روتر Active تبدیل شود، سپس روتر دیگری به عنوان روتر standby انتخاب می شود.
بر روی یک LAN مشخص، چندین گروه standby همزمان می توانند حضور و یا همپوشانی داشته باشند. هر گروه standby یک روتر مجازی را شبیه سازی می کنند. روتری مشخص ممکن است در چندین گروه شرکت داشته باشد. در چنین مواقعی، روتر تایمر و وضعیت هر گروه را به صورت جداگانه نگهداری می کند.
هر گروه standby یک آدرس MAC و یک آدرس IP دارد.
با استفاده از پروتکل HSRP سه نوع از پیام های multicast میان دستگاه ها رد و بدل می شود:
Hello – پیام hello میان دستگاه های Active و Standby ارسال می شود (به صورت پیش فرض هر 3 ثانیه). اگر دستگاه Standby به مدت 10 ثانیه از سمت Active پیامی دریافت نکند، خودش نقش Active را بر عهده خواهد گرفت.
Resign – پیام resign از طرف روترِ active فرستاده می شود، هنگامی که این روتر قرار است آفلاین شود یا به دلایلی از نقش Active صرف نظر کند. این پیام به روتر Standby می گوید که برای نقش Active آماده شود.
Coup – پیام coup هنگامی استفاده می شود که روتر Standby می خواهد به عنوان روتر Active فعال شود (preemption).
روترها در پروتکل HSRP در یکی از وضعیت های زیر قرار می گیرند:
Active – حالتی است که ترافیک در حال ارسال است.
Init یا Disabled – حالتی است که روتر آماده نیست یا قادر به شرکت در فرآیند HSRP نیست.
Learn – حالتی است که هنوز آدرس IP مجازی تعیین نشده است و پیام hello از طرف روتر Active دیده نشده است.
Listen – حالتی است که یک روتر پیام های hello را دریافت می کند.
Speak – حالتی است که روتر پیام های hello را می فرستد و دریافت می کند.
Standby – حالتی است که روتر آماده می شود تا وظایف ارسال ترافیکِ مربوط به روتر Active را بر عهده بگیرد.
ویژگیِ Preemption در HSRP بلافاصله روتری با حداکثر اولویت را به عنوان روتر Active فعال می سازد. اولویت روتر در ابتدا از طریق مقدار priority تعیین می شود که توسط شما تنظیم شده است و سپس به واسطه آدرس IP . هرچه این مقدار بیشتر باشد، اولویت بالاتر است.
وقتی که یک روتر با اولویت بیشتر حق تقدم می یابد، یک پیام coup می فرستد. هنگامی که یک روتر Active با اولویتی کمتر پیامِ coup یا پیامِ hello را از یک روتر با اولویتی بالاتر دریافت کند، به وضعیت speak تغییر می کند و یک پیامِ resign می فرستد.
این ویژگی منجر خواهد شد که فرآیند preemption برای مدت زمانی قابل تنظیم به تعویق بیافتد، و در نتیجه روترِ با اولویت بالا اجازه خواهد یافت که پیش از دریافت نقشِ Active، جدول routing خود را پُر نماید.
این ویژگی به شما اجازه خواهد داد که اینترفیسی را بر روی روتر، برای نظارت بر فرآیند HSRP تعیین نمایید تا اولویت HSRP را برای گروهی معین تغییر دهد.
اگر line protocol مربوط به اینترفیس مشخص شده down شود، اولویت HSRP مربوط به این روتر کاهش یافته است. در نتیجه به روتر دیگری با اولویت بالاتر اجازه داده می شود تا Active شود. برای اینکه از Interafece Tracking در HSRP استفاده نمایید دستور زیر را به کار برید:
[Standby [group] track interface [priority
ویژگی MHSRP به نسخه 10.3 از Cisco IOS اضافه شد. این ویژگی به اشتراک گذاری load و افزونگی در شبکه را در اختیار می گذارد. و اجازه خواهد داد که روترهای افزونه به طور کامل مورد بهره برداری قرار گیرند. در حالی که روتری در نقش Active ترافیکِ یک گروهِ HSRP را ارسال می کند، در همان حال در گروهی دیگر می تواند در وضعیت standby یا listen قرار بگیرد.
آدرس IP مجازی توسط ادمین شبکه کانفیگ می شود. هاست آدرسِ IP مربوط به default gateway خود را برابر با این آدرس IP مجازی خواهد گذاشت و در این حالت روترِ Active به آن پاسخ خواهد داد. آدرس MAC مجازی بر طبق الگوی زیر ایجاد می شود:
##.0000.0C07.AC
بخشِ 0000.0C مربوط به شناسه OUI شرکت Cisco است. بخشِ 07.AC ،شناسه ی اعمال شده برای پروتکلِ HSRP است و ## شناسه ی گروه HSRP است که توسط ادمین شبکه کانفیگ می شود.
**************
برای پروتکل HSRP دو نسخه ارائه شده است که با توجه به نوع سوئیچ لایه 3 یا روتری که در اختیار دارید، می توانید یکی از این دو نسخه را استفاده نمایید. در زیر جدول تفاوت این دو نسخه آورده شده است.
| HSRPV1 | HSRPV2 | ||
|---|---|---|---|
| OP | HTYPE | HLEN | HOPS |
| TRANSACTION ID | |||
| SECS | FLAGS | ||
| CIADDR (Client IP address) | |||
| YIADDR (Your IP address) | |||
| SIADDR (Server IP address) | |||
| GIADDR (Gateway IP address) | |||
| CHADDR (Client hardware address (16 OCTETS)) | |||
| SERVER HOST NAME (64 OCTETS) | |||
| BOOT FILE NAME (128 OCTETS) | |||
| OPTIONS (VARIABLE) | |||
منبع : ویکی پدیا
معماری leaf-spine چگونه است؟
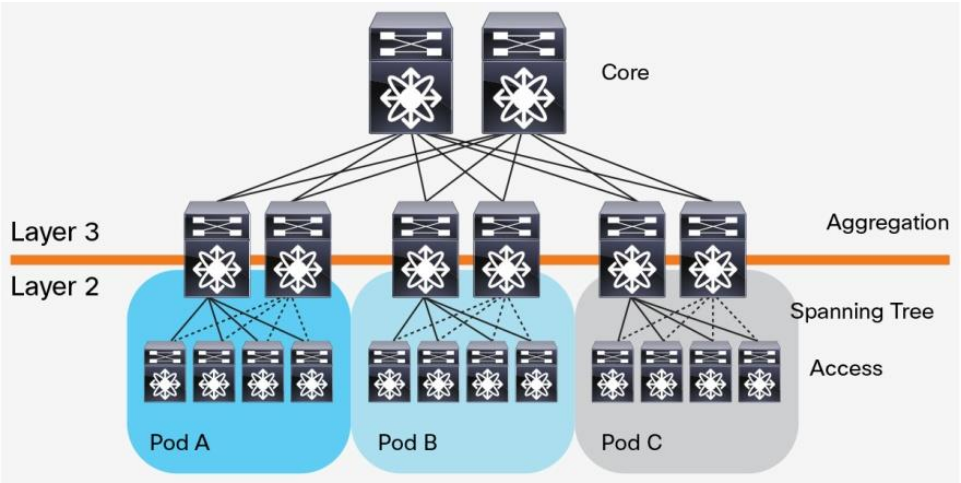
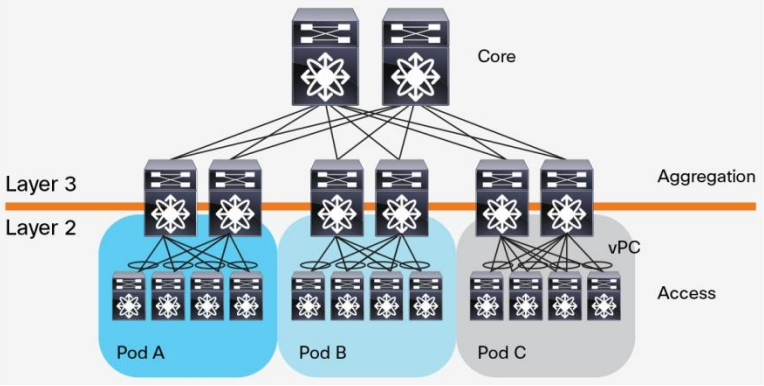
مراکز داده بر تکنولوژی های نرم افزاری جدیدی تکیه می کنند که نقش اساسی را در گسترش قابلیت های یک سازمان enterprise ایفا می کنند. دیتاسنترهای پیشین، معماری three-tier را به کار می برند که در آن سرورها مبتنی بر مکان شان درون pod هایی تقسیم بندی می شوند ( شکل 1)
شکل 1 – طرح سه لایه ای مرکز داده
این معماری شامل روترهای core ، روترهای aggregation (یا همان distribution router) و سوییچ های access می شود. بین روترهای aggregation و سوییچ های access ،از پروتکل STP برای جلوگیری از ایجاد loop در لایه 2 شبکه استفاده می شود. پروتکل STP از چندین ویژگی پشتیبانی می کند: سادگی و تکنولوژی plug-and-play که به تنظیمات اندکی نیاز دارد. VLAN ها درون هر pod بسط داده می شوند به طوری که مکان سرورها آزادانه درون pod ها تغییر می کند بدون اینکه نیازی به تغییر آدرس IP و تنظیماتِ default gateway باشد. با این حال STP نمی تواند از مسیرهای ارسالِ موازی استفاده کند و همیشه مسیرهای افزونه در یک VLAN را مسدود می کند.
در سال 2010 شرکت سیسکو تکنولوژی vPC (یا Virtual-port-channel) ،یا همان Multichassis EtherChannel ،را برای غلبه بر محدودیت STP عرضه نمود. vPC ویژگی است که امکان تنظیم PortChannel را میان چند سوییچ فراهم می کند. vPC مسئله پورت های مسدود شده توسط STP را رفع می کند، مسیرهای uplink ِ active-active را از سوییچ های access به روترهای aggregation فراهم می کند و از پهنای باند موجود بهره کاملی می برد (شکل 2). با استفاده از تکنولوژی vPC ،پروتکل STP همچنان به عنوان مکانیزمی برای fail-safe استفاده می شود.
تکنولوژی vPC (پشتیبانی شده در سوییچ های Nexus سیسکو) به خوبی در محیطِ یک دیتاسنتر نسبتا کوچک ایفای نقش می کند، محیطی که اکثر ترافیک های آن شامل ارتباطات northbound و southbound در میان کلاینت ها و سرورها می شود.
شکل 2 – طرح مرکز داده با استفاده از vPC
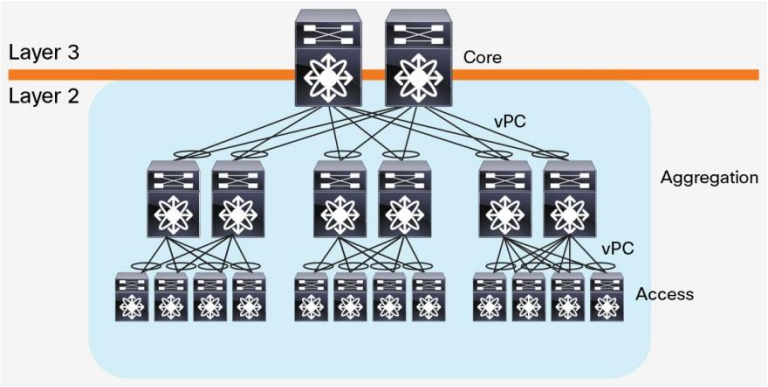
از سال 2003 ،با ارائه تکنولوژی مجازی منابع محاسباتی، شبکه بندی و ذخیره سازی که پیشتر در طرحِ دیتاسنتر، درون pod ها در لایه 2 قرار می گرفتند، حال می توانند یکپارچه شوند. این تکنولوژیِ تحول آور نیاز به domain لایه 2 ای بزرگتری را از لایه access تا لایه core به وجود آورد (شکل 3).
شکل 3 – طرح مرکز داده به همراه domain لایه 3 گسترده
ادمینِ مرکز داده می تواند یک pool مرکزی از منابع با قابلیت تغییرپذیری بیشتر را ایجاد نماید که بر اساس نیازها می توانند دوباره تخصیص دهی شوند. مجموعه ای از VM ها بر روی سرورها قرار دارند که آزادانه از سروری به سرور دیگر قابل جابجایی هستند بدون اینکه به تغییری در پارامترهای عملیاتی خود نیاز داشته باشند.
با استفاده از سرورهای مجازی شده، اپلیکیشن ها به گونه ای در میان سرورها توزیع می شوند که منجر به افزایشِ ترافیک east-west می شود. چنین ترافیکی به مدیریتی موثر به همراهِ تاخیری کم و قابل پیش بینی نیاز خواهد داشت در صورتی که vPC تنها از active بودنِ حداکثر دو uplink موازی پشتیبانی می کند و بنابراین در معماری دیتاسنترِ three-tier ،پهنای باند به یک bottleneck تبدیل می شود. مشکل دیگری که در معماری three-tier وجود دارد، تاخیر سرور-به-سرور است که بسته به مسیر ترافیکی استفاده شده، تغییر می کند.
طرح دیتاسنتر جدیدی با نام معماری leaf-spine که مبتنی بر شبکه clos است برای غلبه بر این محدودیت ها عمومیت یافته است. این معماری ثابت نموده است که پهنای باند بیشتر، تاخیر کمتر و اتصالِ nonblocking سرور-به-سرور را فراهم می کند.
معماری leaf-spine
شکل 4 توپولوژی leaf-spine دو لایه ای را نشان می دهد.
شکل 4 – توپولوژی leaf-spine
در این معماری clos دو لایه ای، هر سوییچ موجود در لایه پایین تر (لایه leaf) به هر یک از سوییچ های لایه بالاتر (لایه spine) از طریق توپولوژیِ full-mesh متصل شده است و هیچ اتصالِ مستقیمی از نوع spine-spine و leaf-leaf وجود ندارد. لایه leaf شامل سوییچ های access می شود که به دستگاه هایی همچون سرورها متصل اند. لایه spine به عنوان ستون فقرات شبکه عمل می کند و در برابر اتصال داخلیِ میان تمامیِ سوییچ های لایه leaf مسئول است. مسیرِ عبور به طور تصادفی انتخاب می شود چنانکه بار ترافیک به صورت یکنواخت میان سوییچ های لایه بالاتر توزیع شود. اگر یکی از سوییچ های لایه بالا دچار خرابی شود، تنها درصد اندکی از کارایی، در سراسر مرکز داده تنزل می یابد.
اگر بار (load) قرار گرفته بر روی لینک بیش از ظرفیت آن باشد (یعنی ترافیک تولید شده بیش از حدی باشد که توسط یک لینک فعال در یک زمان تجمیع شود)، فرآیند افزایشِ ظرفیت ساده است. یک سوییچ spine دیگر افزوده شده و در نتیجه تعداد uplink ها افزایش می یابد که منجر به افزایش پهنای باندِ میانِ لایه ها و کاهش رخدادِ باری بیش از ظرفیت لینک (oversubscription) می شود. اگر ظرفیتِ پورت های دستگاه مورد توجه باشد، می توان یک سوییچِ leaf جدید را از طریق اتصال آن به هر سوییچ spine اضافه نمود و تنظیمات شبکه را به سوییچ افزود. سادگی در توسعه و گسترش این معماری، فرآیند ارتقای شبکه را بهینه می سازد.
همانطور که پیشتر گفته شد طرح معماری سه لایه سنتی از پروتکل STP برای پیشگیری از loop استفاده می کند. پروتکل STP بر اساس شناساییِ loop در شبکه، لینک های افزونه را مسدود می کند. در نتیجه یک سوییچ access که دارای دو عدد uplink است تنها از یکی از آنها می تواند بهره ببرد. معماری leaf-spine پروتکل های جایگزین جدیدتری به نام SPB و TRILL را برای پیشگیری از ایجاد loop به کار می برد. این پروتکل ها اجازه خواهند داد که تمام لینک های بین leaf و spine برای ارسال ترافیک استفاده شوند. پروتکل SPB و TRILL با به کارگیری پروتکل مسیریابی لایه 3 برای دستگاه های لایه 2ای، این مسئله را رفع می نماید. این پروتکل ها به دستگاه های لایه 2 اجازه خواهند داد که فریم های اترنت را مسیریابی نمایند.
با بهره گیری از معماری leaf-spine، مهم نیست که کدام سوییچ در لایه leaf به کدام سوییچ از لایه spine متصل است، ترافیک آن همیشه باید از تعداد دستگاه های یکسانی گذر کند تا به دستِ سرور مقصد برسد (حتی اگر سرور مقصد در همان leaf قرار گرفته باشد). این رویکرد منجر خواهد شد که تاخیر همیشه در سطحی قابل پیشبینی باقی بماند چرا که بسته های داده تنها به سمت یک سوییچ spine و سوییچ leaf دیگر حرکت می کنند تا به مقصد خود برسند.
در پایان
شبکه leaf-spine ویژگی های منحصر به فرد زیادی را در مقابل مدل 3 لایه ای ارائه می دهد. اگر از تنظیمات و طرح مناسب استفاده شود، توپولوژیِ leaf-spine مدیریتِ بارِ بیش از ظرفیت بر لینک (oversubscription) و قابلیت ارتقا را بهبود می بخشد. حذف پروتکلِ STP در این طرح به افزایشِ پایداریِ شبکه منجر می شود. محیط های leaf-spine با بهره مندی از ابزارهای جدید و توانایی در غلبه بر محدودیت های اساسی در کنارِ راهکارهای دیگری همچون SDN ،منجر به رشد و نموِ دپارتمان IT و مراکز داده خواهند شد چرا که خواهند توانست نیازها و خواسته های کسب و کار خود را برآورده نمایند.
منبع :
فاراد سیستم
یکی از محصولات کمپانی قدرتمند هیولت پاکارد ، سرور تیغه ای HP BL460c G9 می باشد . این محصول می تواند جهت استفاده در دیتا سنتر و مجازی سازی مناسب باشد ، همچنین جهت پیکربندی و توسعه در محدوده وسیع طراحی شده است .
برای آشنایی بیشتر با این سرور ها به ادامه مطلب مراجعه نمایید.
ادامه مطلب
امروزه سازمان ها به دنبال این هستند که عملکرد کسب و کار خود را توسعه داده و بار کاری خود را اعم از سنتی و هیبریدی ، به شکل ایمن بر روی یک زیر ساخت یکپارچه ، همگام کنند .
برای آشنایی بیشتر با سرور های BL460c G10 به ادامه مطلب مراجعه نمایید.
ادامه مطلب
VMware و Microsoft اعلام کردند که با یکدیگر همکاری خواهند کرد و در کنفرانس Dell Technologies World در لاس وگاس یک زیرساخت VMware Cloud پشتیبان شده را ارائه خواهد داد که به صورت کاملا بومی روی Microsoft Azure عرضه می شود. همانطور که می دانید VMware یک ارائه دهنده شناخته شده در خدمات مجازی سازی می باشد. آن ها حتی در حال حاضر یک محصول مشابه را از طریق Amazon Web Services ارائه می دهند. سرویس های جدید نه تنها در همکاری با مایکروسافت، بلکه با شرکای VMware Cloud Verified CloudSimple و Virtustream (یک شرکت Dell Technologies) توسعه یافتند.

برای خواندن ادامه خبر به ادامه مطلب مراجعه نمایید. با ما همراه باشید.
ادامه مطلب
یکی از محصولات کمپانی قدرتمند هیولت پاکارد ، سرور تیغه ای HP BL460c G9 می باشد . این محصول می تواند جهت استفاده در دیتا سنتر و مجازی سازی مناسب باشد ، همچنین جهت پیکربندی و توسعه در محدوده وسیع طراحی شده است .
برای آشنایی بیشتر با این سرور ها به ادامه مطلب مراجعه نمایید.
ادامه مطلب
امروزه سازمان ها به دنبال این هستند که عملکرد کسب و کار خود را توسعه داده و بار کاری خود را اعم از سنتی و هیبریدی ، به شکل ایمن بر روی یک زیر ساخت یکپارچه ، همگام کنند .
برای آشنایی بیشتر با سرور های BL460c G10 به ادامه مطلب مراجعه نمایید.
ادامه مطلب




درباره این سایت